
Cyberflex
Cyberflex
Our software team was very intentional in achieving their learning goals of understanding signal processing, optimizing machine learning models, predicting signals in real time, and creating user friendly data collection systems.
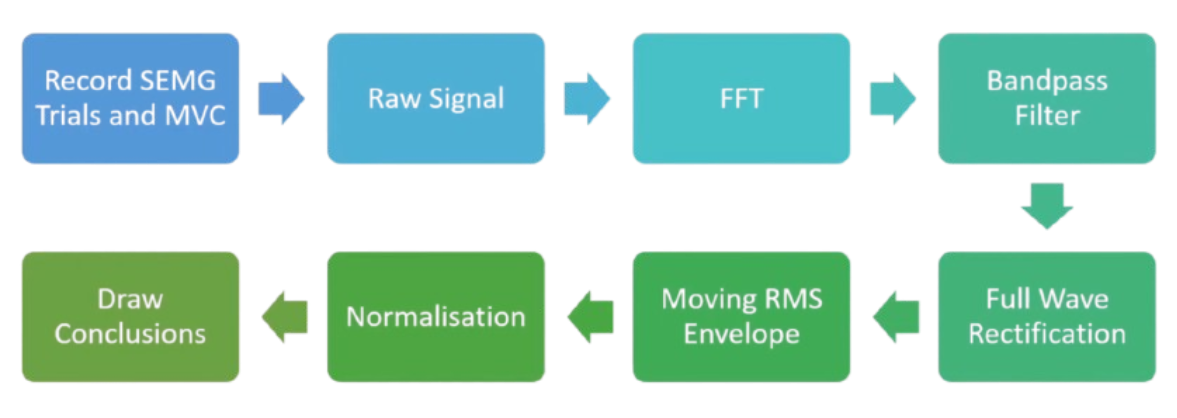
Loading and Reading EMG data:
The sEMG signals are collected from CSV files generated by five sensors attached to the user’s arm. These signals are preprocessed by segmenting them into fixed-size windows with a certain number of samples per window. Each window is labeled with a gesture based on its file name.
Split Data:
The preprocessed dataset is divided into three parts:
Training Set: Used to teach the model the relationship between EMG signals and gestures.
Validation Set: Used to validate the model during training and prevent overfitting.
Test Set: Used to evaluate the model’s final performance and generalization to unseen data. This ensures that the model did not overfit to the training or validation sets.
Define Model Architecture:
This step defines the architecture of the neural network, which is specifically a Convolutional Neural Network (CNN). This type of model is effective for time-series data like EMG signals.
The structure consists of multiple convolutional layers, including batch normalization, pooling, and fully connected layers. A batch normalization layer normalizes the inputs of each layer by scaling and shifting them to improve training speed, stability, and model performance. A pooling layer reduces the spatial dimensions of the input, helping to decrease computational load and prevent overfitting while retaining important features. Finally, the fully connected layer connects every neuron from the previous layer to each neuron in the current layer, enabling the model to make final predictions based on learned features.
These layers allow the CNN to learn meaningful patterns in the data, allowing it to output a prediction of one of the gestures. This is where a lot of our time was spent tuning parameters which gave us the best possible model using our data.
Setup Model:
Loss Function: The loss function used is cross-entropy loss, which measures how well the model predicts the correct gestures by finding the difference between the predicted probabilities and the actual gesture labels while penalizing incorrect predictions more heavily.
Optimizer: The optimizer AdamW is used to adjust the model’s weights during training by minimizing the loss function, this ensures efficient and stable convergence.
Train Model:
The model is trained by iteratively feeding training data through the network, calculating loss, and updating the weights accordingly. Model performance is evaluated after each epoch, which is a single complete pass through the entire training dataset, where the model processes all data points at least once. The model is evaluated on the validation set to avoid overfitting. Validation loss and accuracy is plotted during training to visualize trends and understand model performance.
Evaluate Model:
After training, the model is evaluated using the test set to measure its ability to generalize to new data. The test accuracy reflects how well the model can interpret gestures in real-world scenarios.
Save and Load Model:
Once performance is satisfactory, the trained model is saved for deployment. This allows it to later be loaded and integrated with hardware using a Raspberry Pi. The Raspberry Pi acts as the "brain" in this case with the Arduino sending over the sEMG data collected from the sensors on your arm, the Raspberry Pi predicts what gesture it is, and it sends it back to the Arduino which in turn moves motors to replicate the gesture on a hand.
Finally, we must create a script that can communicate with our firmware to move motors based on the gesture it predicts. To streamline our setup, this is the code which goes on our Raspberry Pi and acts as the brain of our system, taking in sensor values from our firmware and outputting the prediction to our firmware to control our motors.
To create this script, we follow a similar starting process to our data collection script. We set our serial port, baud rate, and window size (which is how much data we’re reading before making a prediction). We then take the CNN architecture we described while training our model and add it to the script. In this case, ours was:
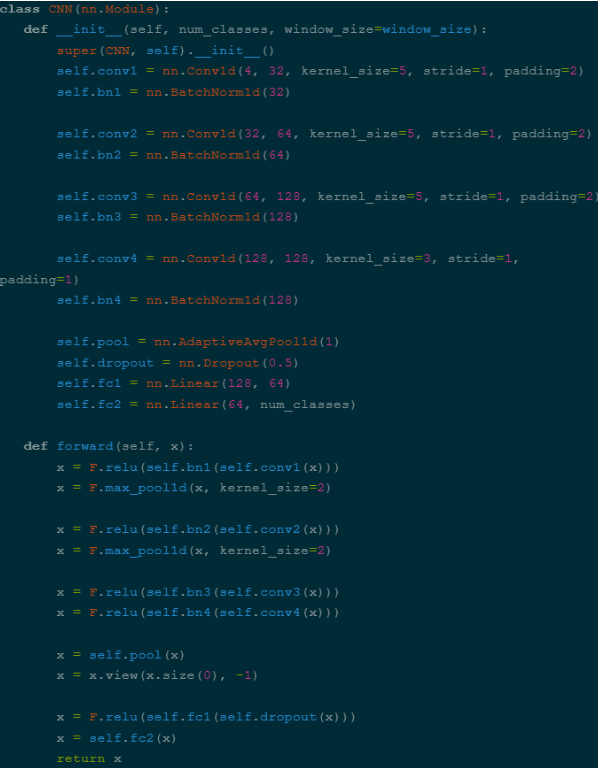
Next we can load the model which we saved from training our model. The one which worked best for us was 9gesture_model.pth, as it had around a 94% accuracy when we trained it. We originally trained a model on 22 gestures but decided to scale back as our accuracy (Just under 90%) wasn’t as high as we hoped it would be. We then set a dictionary of all the values we want to use. For us we included a rock gesture, paper gesture, scissor gesture, phone call gesture, thumb only gesture, pinky only gesture, a three gesture, a four gesture, a spiderman gesture, and a completely relaxed gesture.
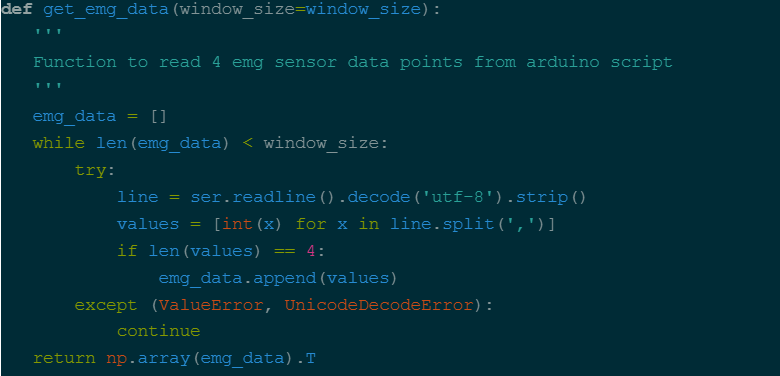
After this, we can create a function which gets emg data from the arduino, storing it in an array.
We can then create a function which uses the loaded model to make a prediction based on the data it collected.
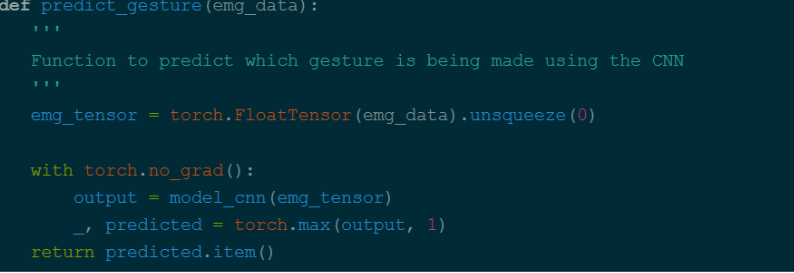
Lastly, we create a function which sends our prediction over to the the arduino so that the firmware code can move motors based on what the gesture was.

We then loop through this until we wish to end the session.
Below is an explanation of everything software and how it was done!
This site was created with the Nicepage